¡Hola a todos!
En el post anterior, les conté todo el paso a paso que seguí para armar mi primer pipeline de datos con Airflow y Docker. Terminado el proyecto, me quedó una pregunta picando: "Ok, tengo los datos llegando a mi base de datos... ¿y ahora qué?".
Porque, seamos honestos, los datos guardados en una tabla son como libros en una estantería juntando polvo. No sirven de nada si nadie los lee.
Así que me propuse un nuevo desafío: tomar un dataset, cargarlo y, esta vez, hacerlo hablar. Quería responder preguntas, encontrar patrones, y tomar decisiones a partir de lo analizado.
El Desafío: El Club de los Unicornios
Encontré en internet un dataset de "Startups Unicornio". O sea, empresas que llegaron a valer más de 1.000 millones de dólares. El dataset eran simples CSV de los que pude identificar relaciones a través de sus claves primarias y foráneas.
Entonces, con ellos quería simular un escenario más real. En una empresa (o en un proyecto serio) los datos no viven en un CSV que se te puede perder; viven en una base de datos, estructurados y ordenados.
Mi plan fue:
- Diseñar un Esquema: Pensar cómo se relacionan los datos. Creé una tabla para Empresas, otra para Industrias, otra para Países, y otra para Inversores.
- Cargar los Datos: Armé unos scripts en Python para leer el CSV y llenar mi base de datos en PostgreSQL, respetando todas esas relaciones.
- Analizar: Con todo ordenado, podía empezar a hacer preguntas.
Este fue el esquema que realicé:
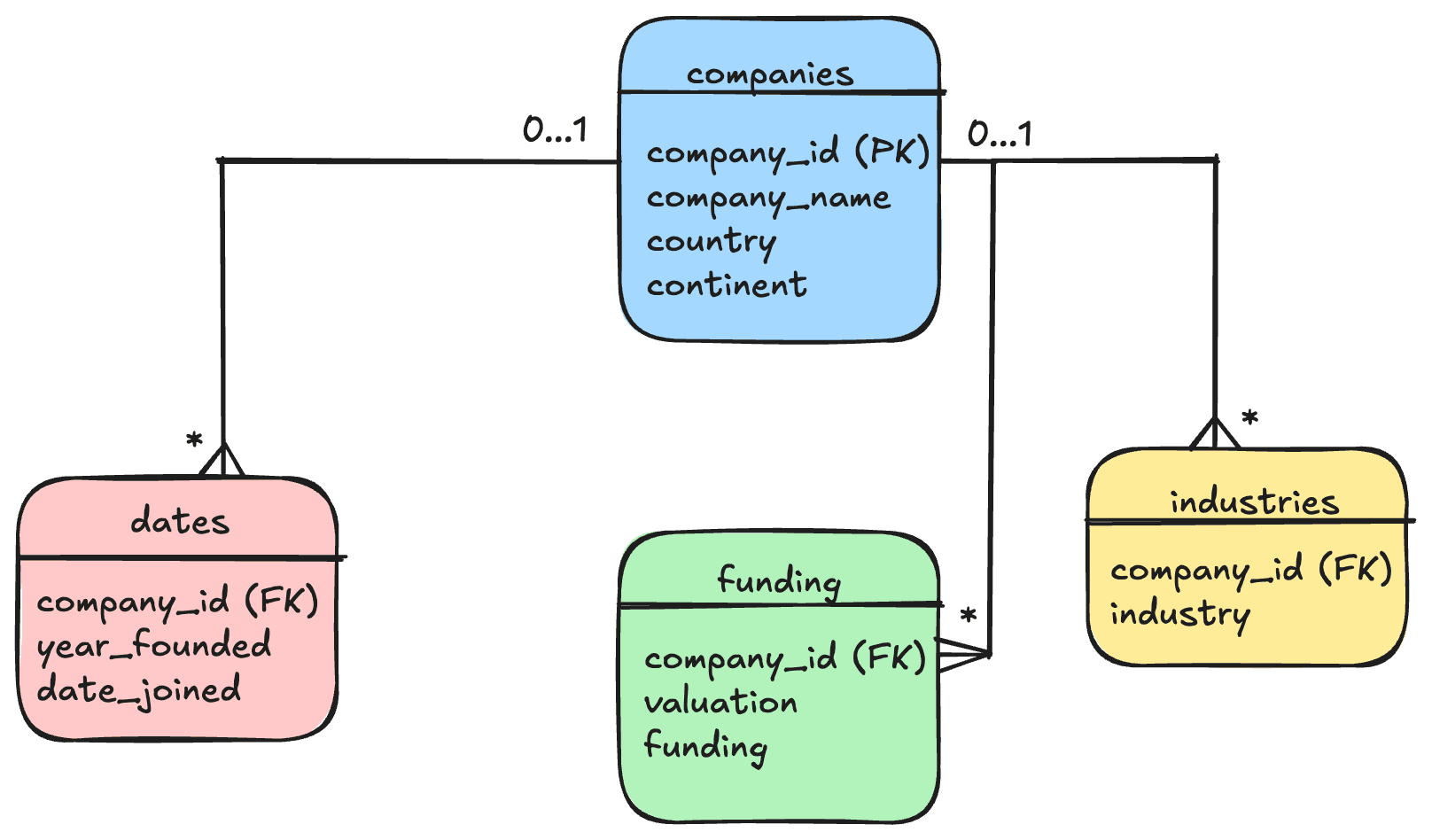
Bien, ya tenía el esquema de la base de datos. Ahora tenía que construilo entonces mi primera decisión fue: utilizar Docker para levantar mi BD. Confecciones mi docker-compose para poder levantar un servidor de PostgreSQL. Con la base de datos ya vivay esperando, ejecuté mis scripts de Python para leer todos los CSV y cargar los datos en las tablas que había diseñado.
Ahora sí, con la base de datos estructurada y poblada, el siguiente paso fue la exploración.
Fase 1: Exploración y validación con SQL
Antes de saltar a Python, mi primera herramienta de elección fue SQL. Sirve para obtener un panorama general de los datos y validar la integridad de las relaciones.
Quería respuestas rápidas a preguntas de alto nivel. Por ejemplo, para identificar los principales centros de startups unicornio, ejecuté una consulta simple:
-- Top 5 países con mayor cantidad de unicornios
SELECT
c.country_name,
COUNT(co.company_id) AS total_unicorns
FROM
companies co
JOIN
countries c ON co.country_id = c.country_id
GROUP BY
c.country_name
ORDER BY
total_unicorns DESC
LIMIT 5;Ejecutar esta consulta (y otras similares que se encuentran en mi script 05_exploratory_data_analysis.sql) arrojó resultados inmediatos. Confirmé la dominancia de mercados como Estados Unidos y China y obtuve un primer vistazo a las industrias más prominentes.
Fase 2: Análisis profundo y visualización con Python
Con las hipótesis iniciales en mano, era momento de pasar a un entorno más robusto para el análisis estadístico y la visualización: Python, específicamente utilizando las librerías Pandas, Matplotlib y Seaborn dentro de Jupyter Notebooks.
El primer paso fue conectar mi script de Python directamente a la base de datos PostgreSQL (usando psycopg2), cargando los resultados de mis consultas SQL en DataFrames de Pandas.
El desafío: Limpieza y transformación de datos
Un hallazgo clave fue que ciertos campos, como el de los inversores, no estaban atomizados. Era común encontrar múltiples inversores listados en una sola cadena de texto (ej: "Sequoia Capital, Tiger Global Management, SoftBank Vision Fund").
Para analizar la influencia de inversores individuales, tuve que aplicar técnicas de limpieza de datos:
- Dividir (split) la celda en múltiples filas.
- Limpiar (strip) espacios en blanco y caracteres anómalos.
- Agrupar y contar las apariciones para identificar a los inversores más activos.
Este proceso, esta detallado en el notebook analisis_unicornios.ipynb.
Hallazgos: Respondiendo las Preguntas de Negocio
Una vez limpios y estructurados los datos, me centré en responder las preguntas de negocio clave, enfocándome en el período crítico de 2019 a 2021.
Pregunta 1: ¿Cuántas empresas alcanzaron el estatus de unicornio ($1B+) entre 2019-2021?
El análisis reveló un total de 69 nuevos unicornios en este período.
| Año | Nuevos Unicornios | Crecimiento (Año a Año) |
|---|---|---|
| 2019 | 5 | - |
| 2020 | 7 | +40% |
| 2021 | 57 | +714% |
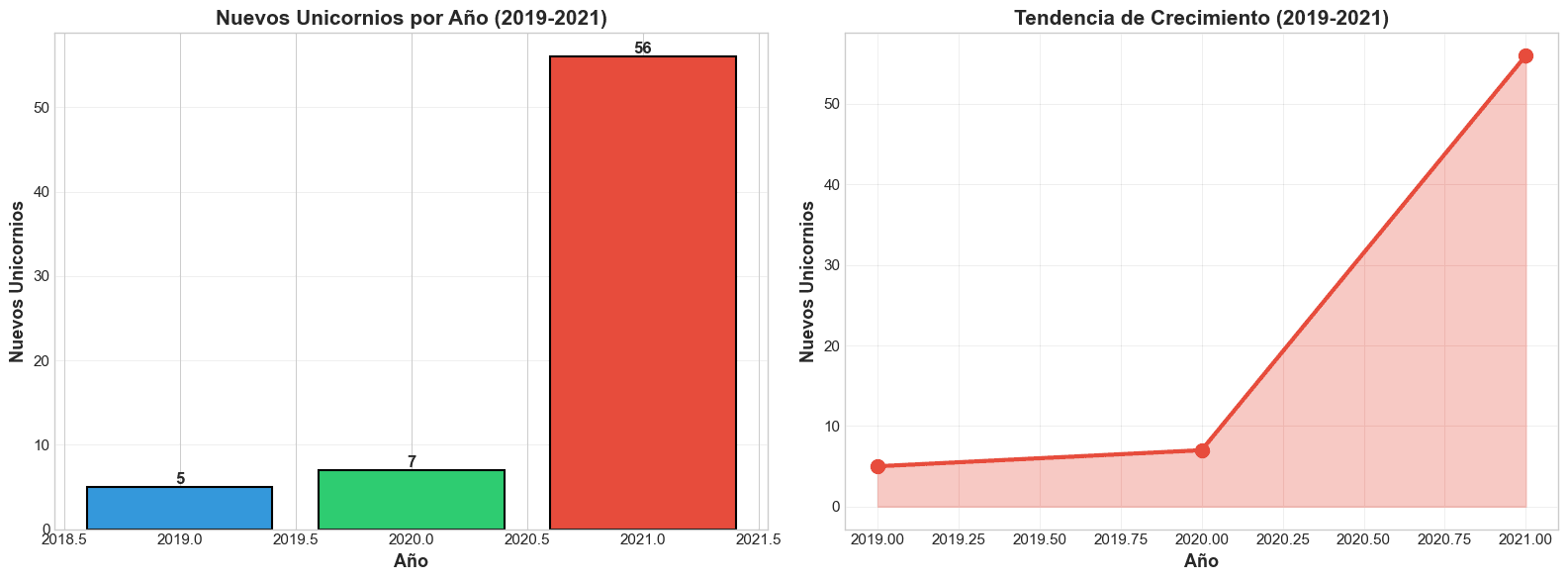
Insight Clave: El crecimiento en 2021 fue explosivo. Esto sugiere un boom masivo en el capital de riesgo.
Pregunta 2: ¿Qué sectores están en auge?
El análisis de los 69 unicornios de este período muestra una clara dominancia de ciertos sectores.
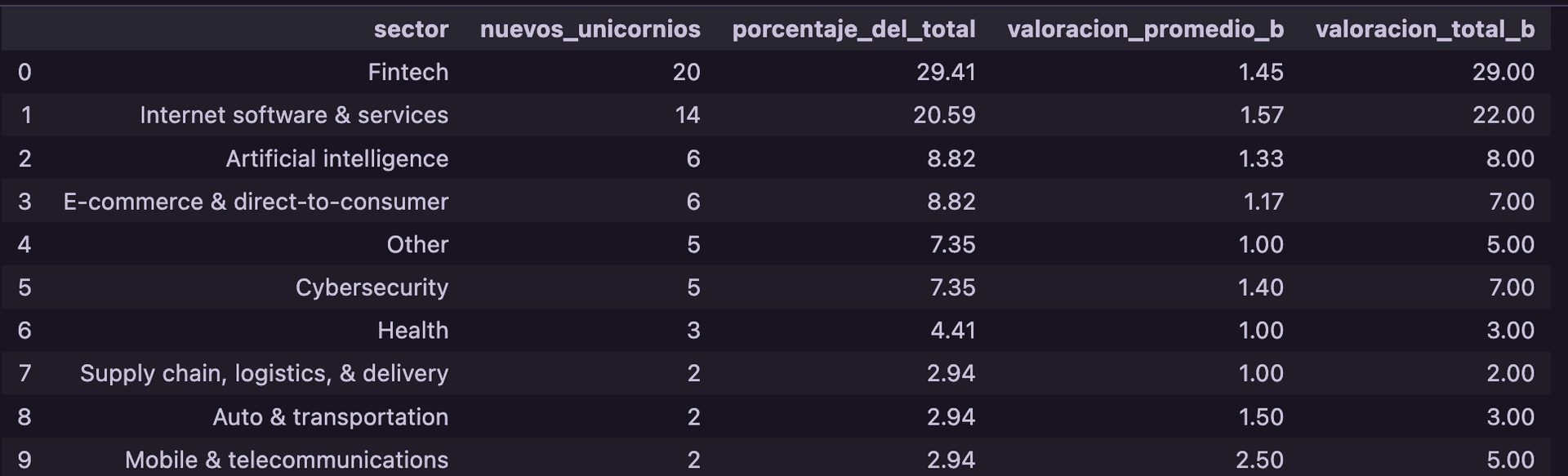
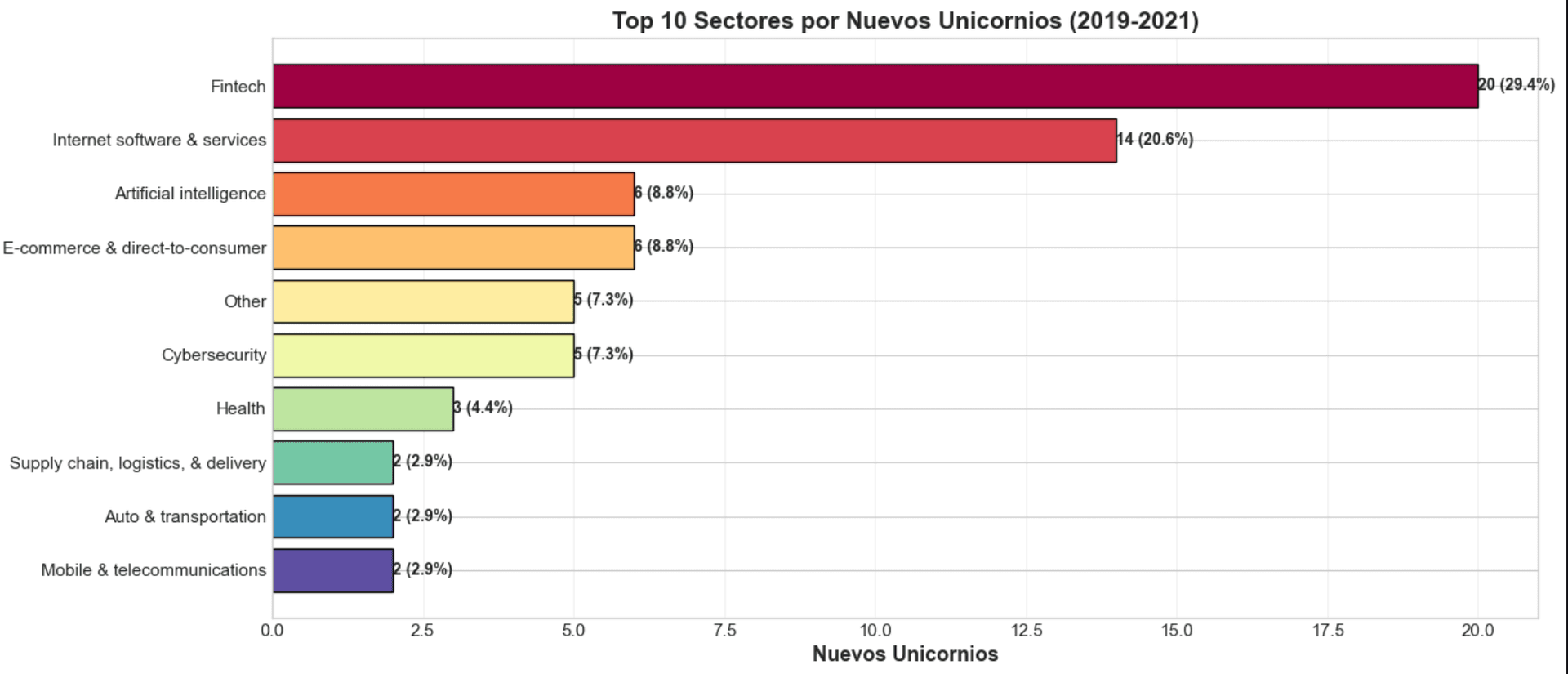
Insight Clave: Fintech y E-commerce lideran, pero la irrupción de AI/ML como sector nuevo es notable.
Pregunta 3: ¿Dónde debería invertir un fondo de capital riesgo?
Basado en los datos, sinteticé un "Score de Inversión"combinando volumen, eficiencia de capital (Ratio Valuación/Funding) y velocidad (Años para ser unicornio).
Recomendación #1: Fintech (Score: 78.5/100)
- Volumen: 18 unicornios (Líder del mercado).
- Eficiencia (Ratio Val/Funding): 16.5 (Muy eficiente).
- Velocidad (Años a unicornio): 4.2 años (Muy rápido).
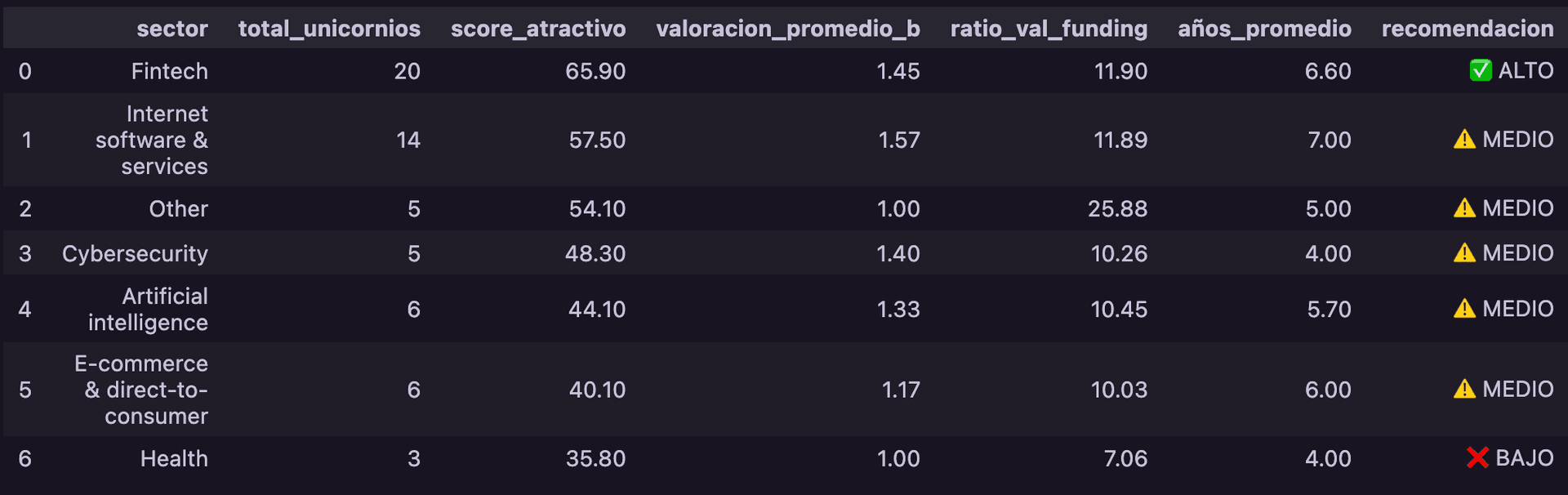
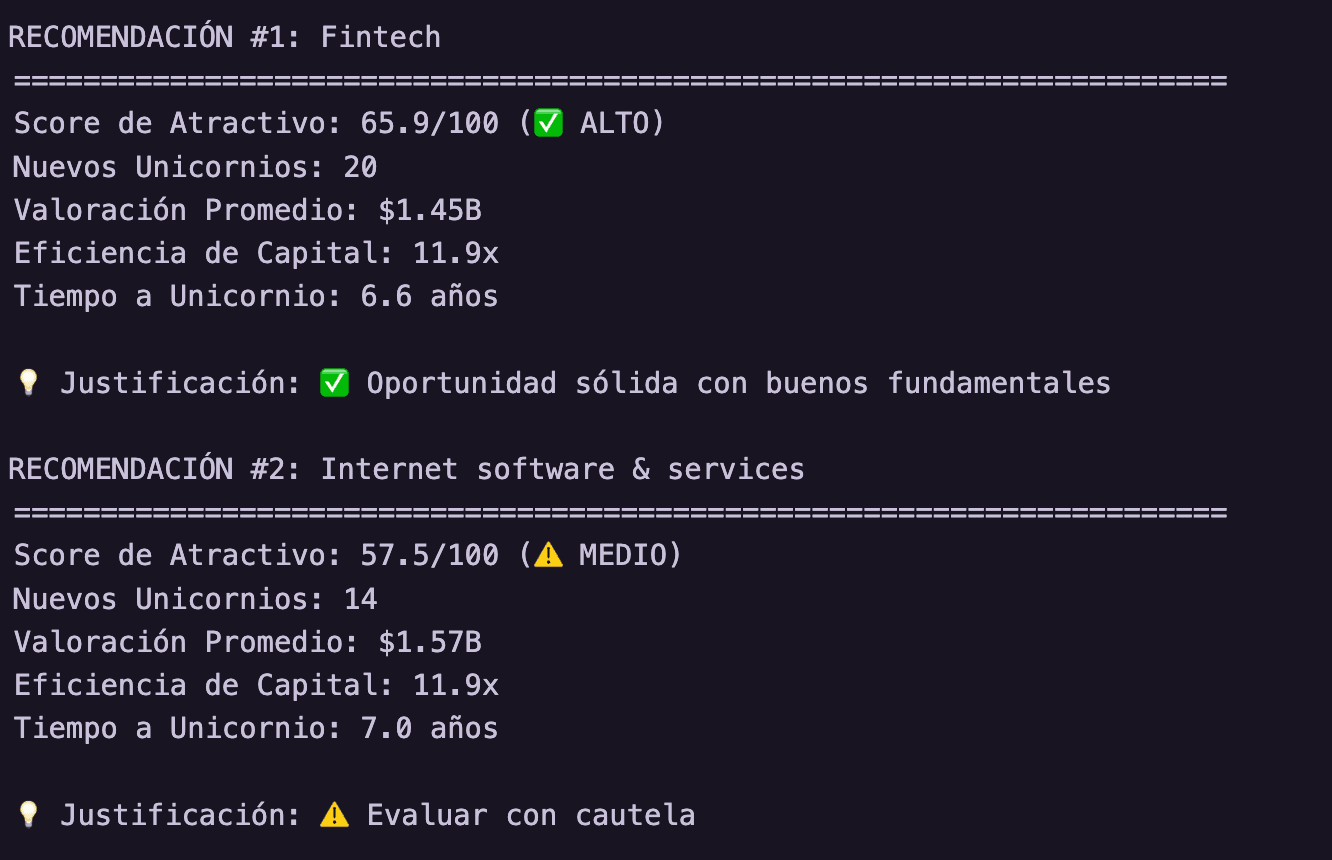
Justificación: Fintech combina un fuerte momentum de mercado (lidera en volumen) con una notable eficiencia en el uso del capital y un rápido crecimiento, por ende, es la mejor decisión a la hora de elegir nuestras inversiones
Conclusiones del análisis
Este proyecto fue un ejercicio completo que cubrió todo el espectro del análisis de datos:
- Diseño de Base de Datos: Estructurar un esquema relacional normalizado.
- Ingesta de Datos (ETL): Usar Python para poblar la base de datos.
- Exploración (EDA): Emplear SQL para consultas rápidas y validación.
- Análisis y Limpieza: Utilizar Pandas para transformar datos compejos.
- Análisis de Negocio: Sintetizar datos crudos en insights y recomendaciones accionables.
La lección más importante fue la sinergia entre SQL y Python. SQL es la herramienta superior para la extracción y agregación eficiente de datos a nivel de servidor, mientras que Python proporciona la flexibilidad necesaria para la limpieza avanzada, el análisis estadístico y la visualización.
Todo el código, las consultas SQL y los notebooks de este análisis están disponibles en mi repositorio de GitHub.